智谱GLM-4.6V实测国产最强多模态Agent底座模型
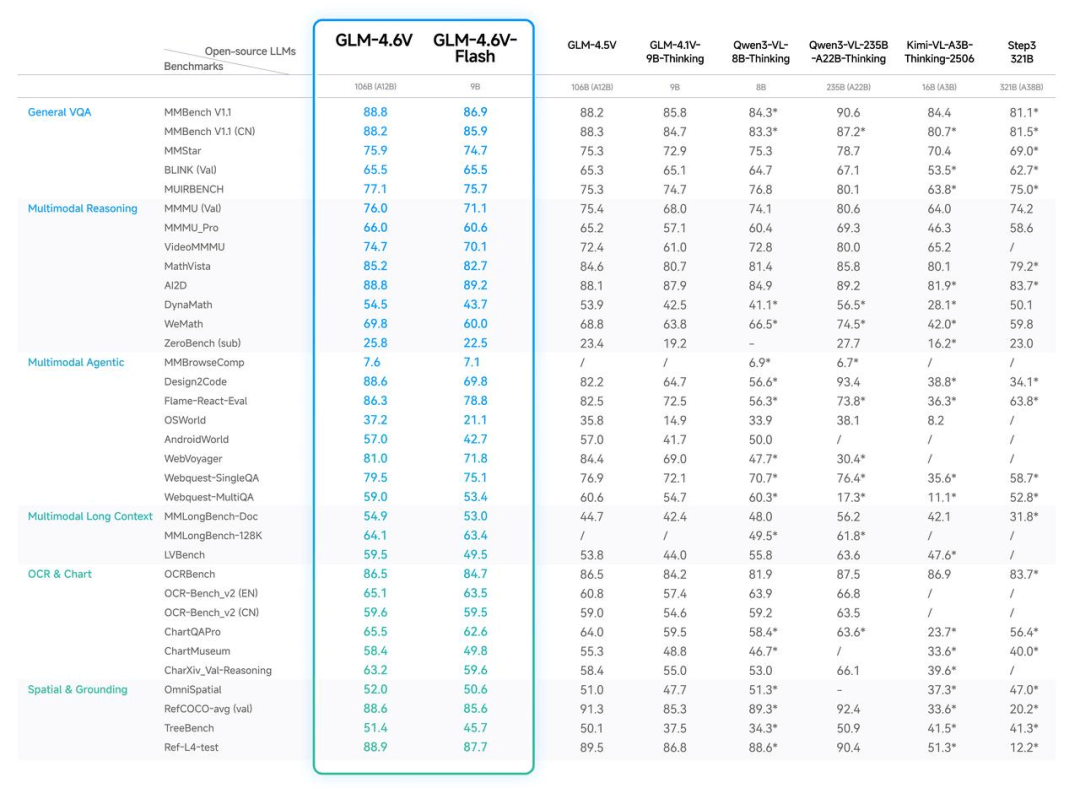
视觉推理领域迎来重大突破,GLM-4.6V系列模型以开源姿态重塑多模态AI格局,两大版本各具优势。
此次发布包含两个重要版本:
- GLM-4.6V:具备106B总参数规模,单次推理激活12B参数,视觉理解精度达到同参数级别最优水平,专为云端及高性能场景优化;
- GLM-4.6V-Flash:精简至9B总参数,体积更小响应更快,特别适合本地化部署需求;
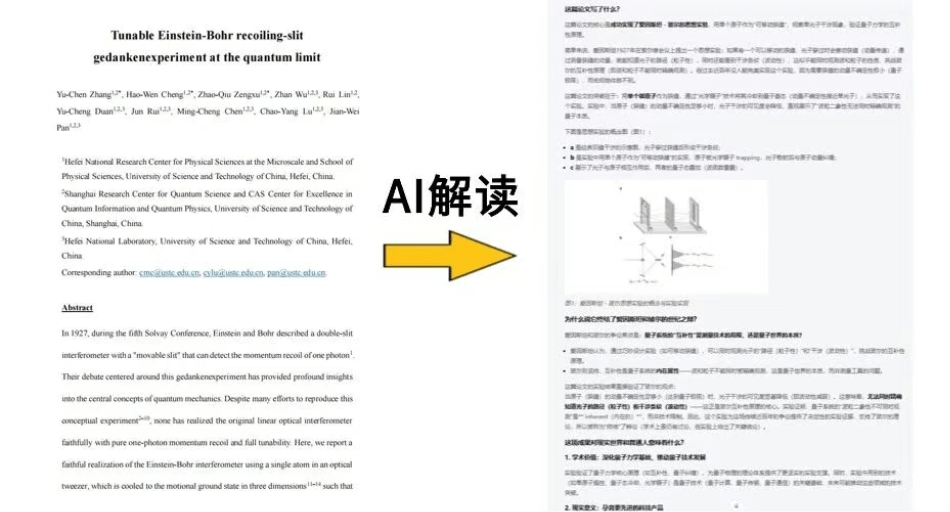
该系列首创性整合Function Call功能,赋予视觉模型工具调用能力,使AI既能准确识别图像内容,又能主动调用工具执行后续操作。以学术论文处理为例,模型可自动解析包含复杂图表的研究文献,并转化为通俗易懂的图文内容。
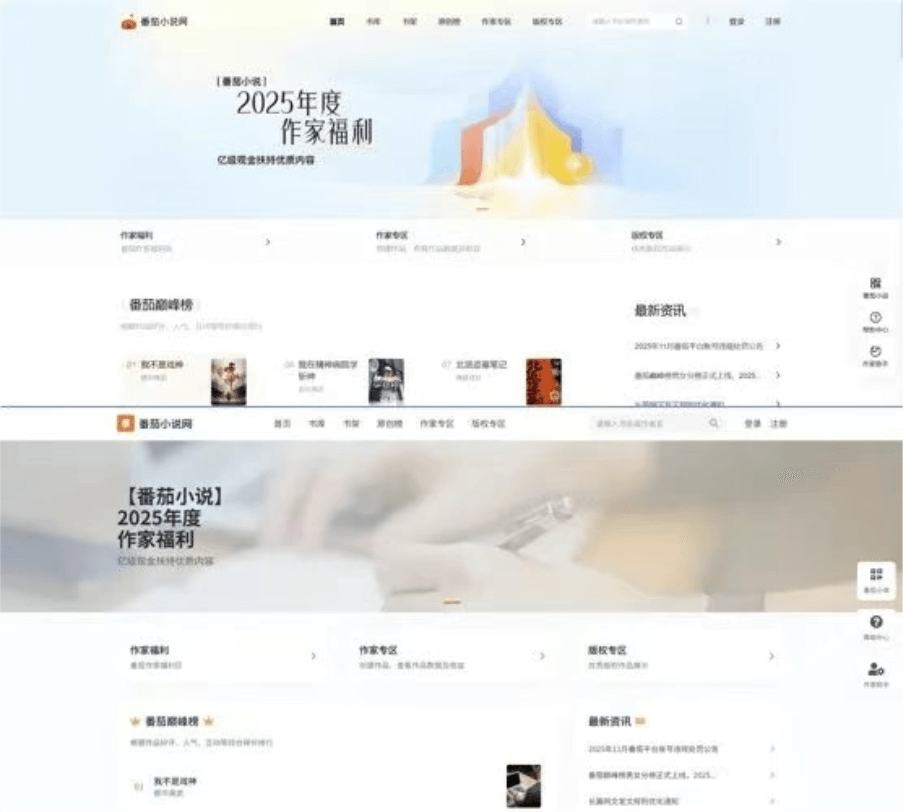
其网页复刻能力尤为突出,仅需单张截图即可精准还原页面结构与设计元素。
01. 功能实测
用户可通过指定平台体验模型功能,主要访问渠道包括:
官方平台:https://chat.z.ai
开源仓库:https://github.com/zai-org/GLM-V
模型社区:https://huggingface.co/collections/zai-org/glm-46v
模型支持四大核心工具:图像识别、图像处理、图像搜索和购物搜索。平台提供预设功能模板,涵盖智能比价、文档解析等典型场景,用户选择后系统自动匹配相应工具链。
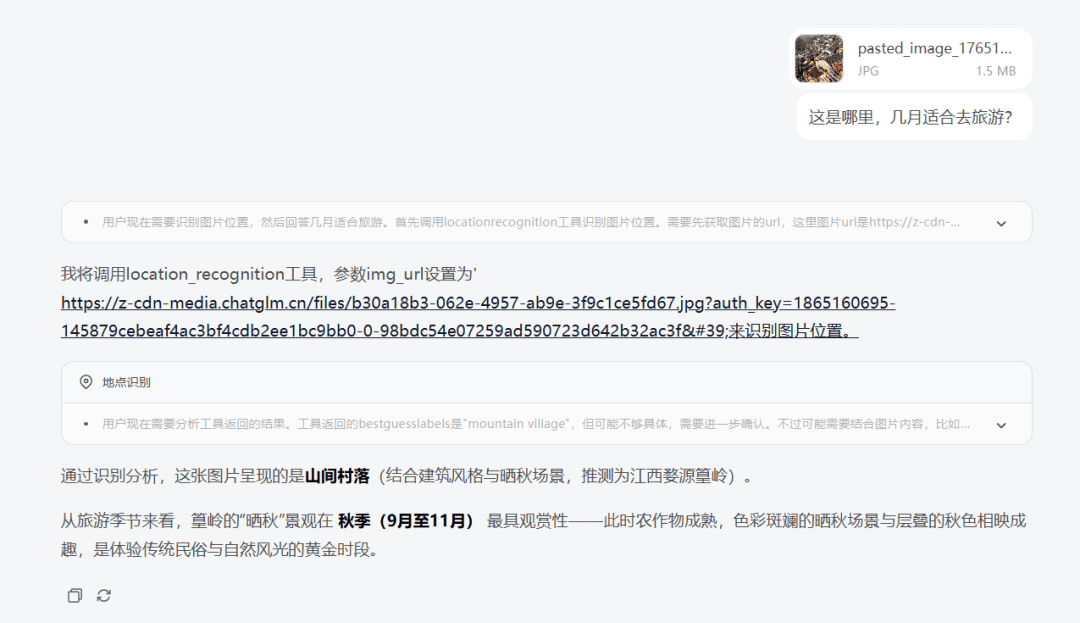
场景1 智能识图
输入:这是哪里,几月适合去旅游?

模型通过视觉识别与知识检索的协同工作,准确解析图像内容并给出旅行建议。
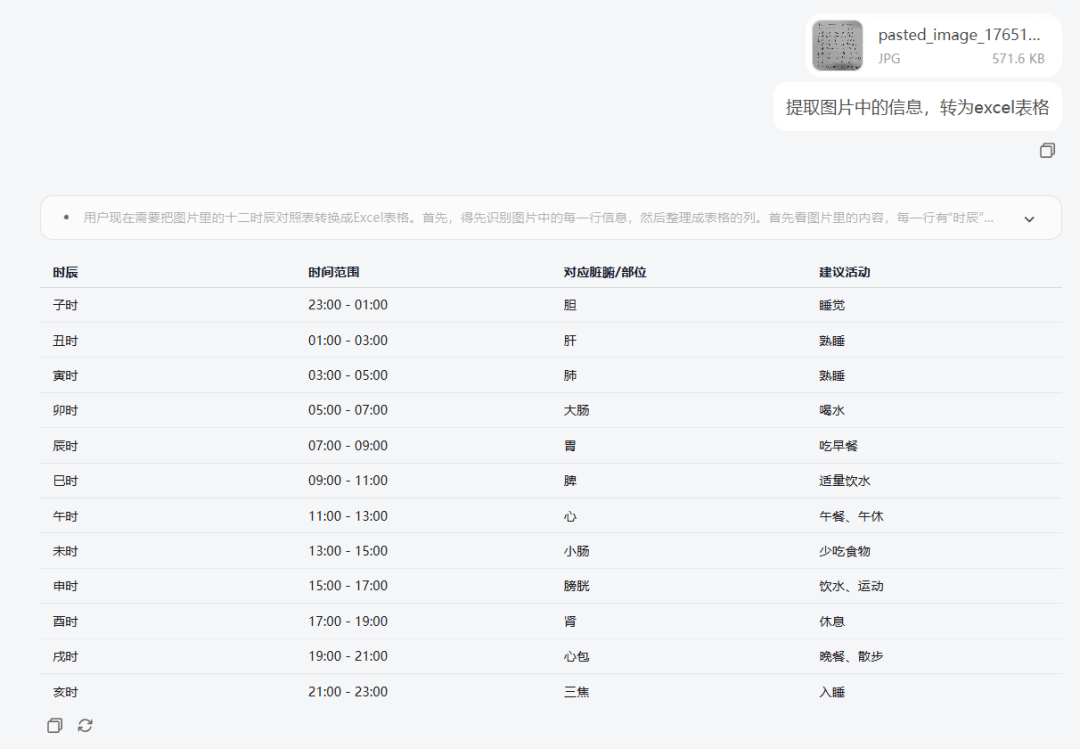
场景2 表格转换
输入:提取图片中的信息,转为excel表格。

模型展现出卓越的版面分析与数据提取能力。
进阶测试中,模型成功识别宠物食品成分表,并给出专业喂养建议:
输入:帮我扫描出来这款猫粮的原料、成分表和其他说明,并分析适合2岁小猫长期吃吗?
场景3 文献解析
针对潘建伟团队发表在PRL的量子物理突破性论文,模型展现出强大的学术解析能力:
输入:用通俗易懂的话说明:这篇论文写了什么,为什么说它终结了爱因斯坦和玻尔的世纪之辩,以及这项成果除了学术价值之外,对现实世界和普通人意味着什么。
模型不仅准确解析复杂图表,还能将核心论点转化为大众可理解的表达形式。
场景4 影视分析
输入:这是白日梦想家的经典片段,它具体用到了哪些镜头语言,分镜设计有什么亮点?
模型提供的专业镜头语言分析远超普通观众理解水平,完整还原了导演的创作意图。
场景5 数学解题
输入:解答图中问题。
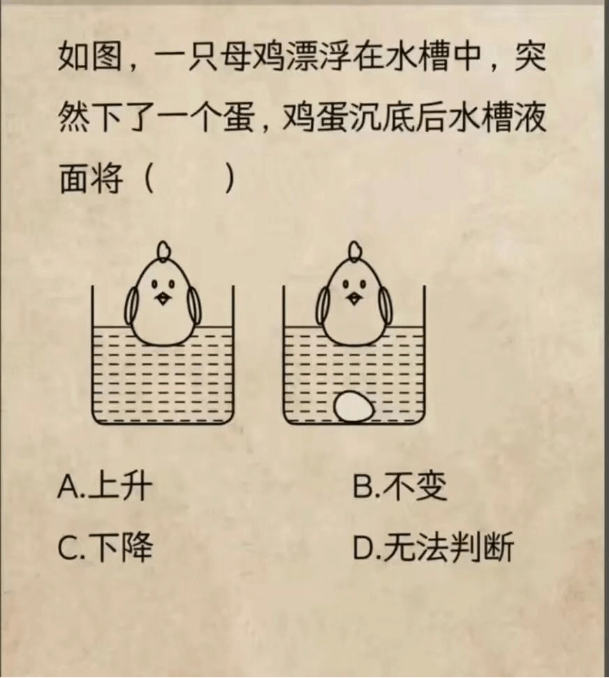
模型展现出优秀的视觉推理能力,解题步骤清晰合理。

场景6 商品比价
输入:请帮我搜索与图中赵露思耳环类似的平价同款。

模型精准识别饰品特征,提供跨平台比价方案。

场景7 内容生成
输入:搜索一下视觉模型的发展过程,生成一个图文并茂的报告。
场景8 网页复刻
输入:复刻截图中的网页,页面中涉及的所有图片素材必须直接使用真实图片和视频,不要用 placeholder 或占位元素。