JavaScript字符串常见基础方法精讲

【相关推荐:javascript视频教程、web前端】
不论在何种编程语言中,字符串都是重要的数据类型,跟随我了解更多JavaScript字符串知识吧!
前言
字符串就是由字符组成的串,如果学习过C、Java就应该知道,字符本身也可以独立成为一个类型。但是,JavaScript没有单个的字符类型,只有长度为1的字符串。
JavaScript的字符串采用固定的UTF-16编码,不论我们编写程序时采用何种编码,都不会影响。
写法
字符串有三种写法:单引号、双引号、反引号。
let single = 'abcdefg';//单引号let double = "asdfghj";//双引号let backti = `zxcvbnm`;//反引号
单、双引号具有相同的地位,我们不做区分。
字符串格式化
反引号允许我们使用${...}优雅的格式化字符串,取代使用字符串加运算。
let str = `I'm ${Ma***round(18.5)} years old.`;co***le.log(str);代码执行结果:

多行字符串
反引号还可以允许字符串跨行,当我们编写多行字符串的时候非常有用。
let ques = `Is the author handsome?
A. Very handsome;
B. So handsome;
C. Super handsome;`;co***le.log(ques);代码执行结果:
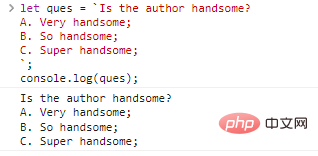
是不是看起来觉得也没有什么?但是使用单双引号是不能实现的,如果想要得到同样的结果可以这么写:
let ques = 'Is the author handsome?nA. Very handsome;nB. So handsome;nC. Super handsome;';co***le.log(ques);以上代码包含了一个特殊字符n,它是我们编程过程中最常见的特殊字符了。
特殊字符
字符n又名"换行符",支持单双引号输出多行字符串。当引擎输出字符串时,若遇到n,就会另换一行继续输出,从而实现多行字符串。
虽然n看起来是两个字符,但是只占用一个字符位置,这是因为在字符串中是转义符,被转义符修饰的字符就变成了特殊字符。
特殊字符列表
| 特殊字符 | 描述 |
|---|---|
n | 换行符,用于新起一行输出文字。 |
r | 回车符,将光标移到行首,在Windows系统中使用rn表示一个换行,意思是光标需要先到行首,然后再到下一行才可以换一个新的行。其他系统直接使用n就可以了。 |
' " | 单双引号,主要是因为单双引号是特殊字符,我们想在字符串中使用单双字符就要转义。 |
\ | 反斜杠,同样因为 |
b f v | 退格、换页、垂直标签——已经不再使用。 |
xXX | 编码为XX的十六进制Unicode字符,例如:x7A表示z(z的十六进制Unicode编码为7A)。 |
uXXXX | 编码为XXXX的十六进制Unicode字符,例如:u00A9表示 © 。 |
u{X...X}(1-6个十六进制字符) | UTF-32编码为X...X的Unicode符号。 |
举个例子:
co***le.log('I'm a st***nt.';);// 'co***le.log(""I love U"");// "co***le.log("\n is new line character.");// nco***le.log('u00A9')// ©co***le.log('u{1F60D}');//
代码执行结果:
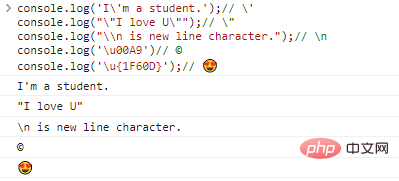
有了转义符的存在,理论上我们可以输出任何字符,只要找到它对应的编码就可以了。
避免使用'、"
对于字符串中的单双引号,我们可以通过在单引号中使用双引号、在双引号中使用单引号,或者直接在反引号中使用单双引号,就可以巧妙的避免使用转义符,例如:
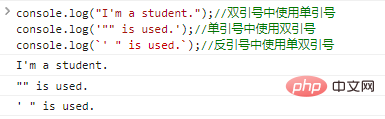
co***le.log("I'm a student."); //双引号中使用单引号co***le.log('"" is us***';); //单引号中使用双引号co***le.log(`' " is used.`); //反引号中使用单双引号
代码执行结果如下:
.length
通过字符串的.length属性,我们可以获得字符串的长度:
co***le.log("HelloWorldn".length);//11这里n只占用了一个字符。
《基础类型的方法》章节我们探究了
JavaScript中的基础类型为什么会有属性和方法,你还记得吗?
访问字符、charAt()、for…of
字符串是字符组成的串,我们可以通过[字符下标]访问单个的字符,字符下标从0开始:
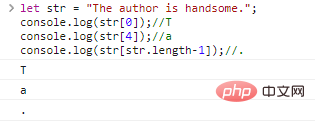
let str = "The author is handsome."; co***le.log(str[0]);//Tco***le.log(str[4]);//aco***le.log(str[st***ength-1]);//.
代码执行结果:
我们还可以使用charAt(post)函数获得字符:
let str = "The author is handsome.";co***le.log(st***harAt(0)); //Tco***le.log(st***harAt(4)); //aco***le.log(st***harAt(st***ength-1));//.
二者执行效果完全相同,唯一的区别在于越界访问字符时:
let str = "01234";co***le.log(str[9]);//undefinedco***le.log(st***harAt(9));//""(空串)
我们还可以使用for ..of遍历字符串:
for(let c of '01234'){
co***le.log(c);}字符串不可变
JavaScript中的字符串一经定义就不可更改,举个例子:
let str = "Const";str[0] = 'c' ;co***le.log(str);代码执行结果:
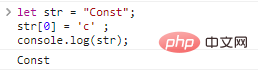
如果想获得一个不一样的字符串,只能新建:
let str = "Const";str = st***eplace('C','c');co***le.log(str);
看起来我们似乎改变了字符串,实际上原来的字符串并没有被改变,我们得到的是replace方法返回的新字符串。
.toLowerCase()、.toUpperCase()
转换字符串大小写,或者转换字符串中单个字符的大小写。
这两个字符串的方法比较简单,举例带过:
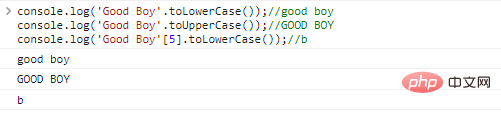
co***le.log('Good Boy'.toLowerCase());//good boyco***le.log('Good Boy'.toUpperCase());//GOOD BOYco***le.log('Good Boy'[5].toLowerCase());//b
代码执行结果:
.indexOf()、.lastIndexOf() 查找子串
.indexOf(substr,idx)函数从字符串的idx位置开始,查找子串substr的位置,成功返回子串首字符下标,失败返回-1。
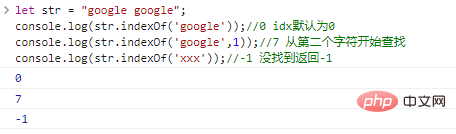
let str = "google google";co***le.log(st***ndexOf('google')); //0 idx默认为0co***le.log(st***ndexOf('google',1)); //7 从第二个字符开始查找co***le.log(st***ndexOf('xxx')); //-1 没找到返回-1
代码执行结果:
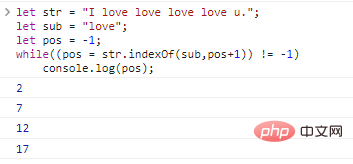
如果我们想查询字符串中所有子串位置,可以使用循环:
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = st***ndexOf(sub,pos+1)) != -1) co***le.log(pos);
代码执行结果如下:
.lastIndexOf(substr,idx)倒着查询子串,首先查找最后一个符合的串:
let str = "google google";co***le.log(st***astIndexOf('google'));//7 idx默认为0
按位取反技巧(不推荐,但要会)
由于indexOf()和lastIndexOf()方法在查询不成功的时候会返回-1,而~-1 === 0。也就是说只有在查询结果不为-1的情况下使用~才为真,所以我们可以:
let str = "google google";if(~indexOf('google',str)){
...}通常情况下,我们不推荐在不能明显体现语法特性的地方使用一个语法,这会在可读性上产生影响。好在以上代码只出现在旧版本的代码中,这里提到就是为了大家在阅读旧代码的时候不会产生困惑。
补充:
~是按位取反运算符,例如:十进制的数字2的二进制形式为0010,~2的二进制形式就是1101(补码),也就是-3。简单的理解方式,
~n等价于-(n+1),例如:~2 === -(2+1) === -3
.includes()、.startsWith()、.endsWith()
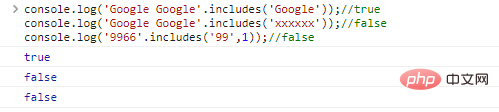
.includes(substr,idx)用于判断substr是否在字符串中,idx是查询开始的位置co***le.log('Google Google'.includes('Google'));//trueco***le.log('Google Google'.includes('xxxxxx'));//falseco***le.log('9966'.includes('99',1));//false
代码执行结果:
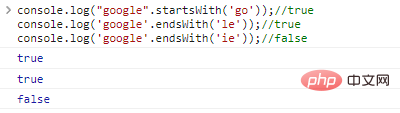
.startsWith('substr')和.endsWith('substr')分别判断字符串是否以substr开始或结束co***le.log("google".startsWith('go'));//trueco***le.log('google'.endsWith('le'));//trueco***le.log('google'.endsWith('ie'));//false
代码执行结果:
.substr()、.substring()、.slice()
.substr()、.substring()、.slice()均用于取字符串的子串,不过用法各有不同。
.substr(start,len)返回字符串从
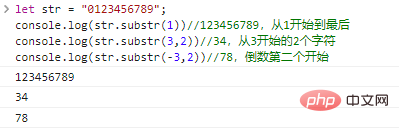
start开始len个字符组成的字符串,如果省略len,就截取到原字符串的末尾。start可以为负数,表示从后往前第start个字符。let str = "0123456789";co***le.log(st***ubstr(1))//123456789,从1开始到最后co***le.log(st***ubstr(3,2))//34,从3开始的2个字符co***le.log(st***ubstr(-3,2))//78,倒数第二个开始
代码执行结果:
.slice(start,end)返回字符串从
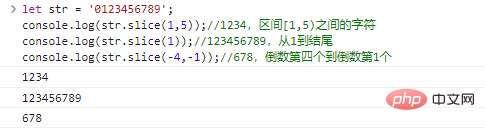
start开始到end结束(不包括)的字符串。start和end可以为负数,表示倒数第start/end个字符。let str = '0123456789';co***le.log(st***lice(1,5));//1234,区间[1,5)之间的字符co***le.log(st***lice(1));//123456789,从1到结尾co***le.log(st***lice(-4,-1));//678,倒数第四个到倒数第1个
代码执行结果:
.substring(start,end)作用几乎和
.slice()相同,差别在两个地方:- 允许
end > start; - 不允许负数,负数视为
0;
举例:
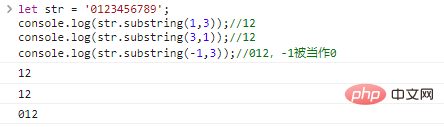
let str = '0123456789';co***le.log(st***ubstring(1,3));//12co***le.log(st***ubstring(3,1));//12co***le.log(st***ubstring(-1,3));//012,-1被当作0
代码执行结果:
- 允许
对比三者的区别:
| 方法 | 描述 | 参数 |
|---|---|---|
.slice(start,end) | [start,end) | 可负 |
.substring(start,end) | [start,end) | 负值为0 |
.substr(start,len) | 从start开始长为len的子串 | 可负 |
方法多了自然就选择困难了,这里建议记住
.slice()就可以了,相比于其他两种更灵活。
.codePointAt()、St***g.fromCodePoint()
我们在前文中已经提及过字符串的比较,字符串按照字典序进行排序,每个字符背后都是一个编码,ASCII编码就是一个重要的参考。
例如:
co***le.log('a'>'Z');//true字符之间的比较,本质上是代表字符的编码之间的比较。JavaScript使用UTF-16编码字符串,每个字符都是一个16为的代码,想要知道比较的本质,就需要使用.codePointAt(idx)获得字符的编码:
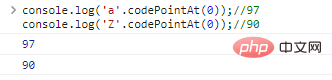
co***le.log('a'.codePointAt(0));//97co***le.log('Z'.codePointAt(0));//90
代码执行结果:
使用St***g.fromCodePoint(code)可以把编码转为字符:
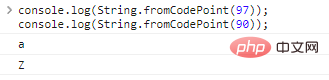
co***le.log(St***g.fromCodePoint(97));co***le.log(St***g.fromCodePoint(90));
代码执行结果如下:
 St***g.fromCodePoint
St***g.fromCodePoint
这个过程可以用转义符u实现,如下:
co***le.log('u005a');//Z,005a是90的16进制写法co***le.log('u0061');//a,0061是97的16进制写法
下面我们探索一下编码为[65,220]区间的字符:
let str = '';for(let i = 65; i<=220; i++){
str+=St***g.fromCodePoint(i);}co***le.log(str);代码执行部分结果如下:

上图并没有展示所有的结果,快去试试吧。
.localeCompare()
基于国际化标准ECMA-402,JavaScript已经实现了一个特殊的方法(.localeCompare())比较各种字符串,采用st***localeCompare(str2)的方式:
- 如果
str1 < str2,返回负数; - 如果
str1 > str2,返回正数; - 如果
str1 == str2,返回0;
举个例子:
co***le.log("abc".localeCompare('def'));//-1为什么不直接使用比较运算符呢?
这是因为英文字符有一些特殊的写法,例如,á是a的变体:
co***le.log('á' < 'z');//false虽然也是a,但是比z还要大!!
此时就需要使用.localeCompare()方法:
co***le.log('á'.localeCompare('z'));//-1常用方法
str.trim()去除字符串前后空白字符,st***rimStart()、st***rimEnd()删除开头、结尾的空格;let str = " 999 ";co***le.log(str.trim());//999st***epeat(n)重复n次字符串;let str = '6';co***le.log(st***epeat(3));//666
st***eplace(substr,newstr)替换第一个子串,st***eplaceAll()用于替换所有子串;let str = '9+9';co***le.log(st***eplace('9','6'));//6+9co***le.log(st***eplaceAll('9','6'));//6+6
还有很多其他方法,我们可以访问手册获取更多知识。
进阶内容
生僻字、emoji、特殊符号
JavaScript使用UTF-16编码字符串,也就是使用两个字节(16位)表示一个字符,但是16位数据只能表示65536个字符,对于常见字符自然不在话下,但是对于生僻字(中文的)、emoji、罕见数学符号等就力不从心了。
这种时候就需要扩展,使用更长的位数(32位)表示特殊字符,例如:
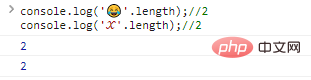
co***le.log(''.length);//2co***le.log('?'.length);//2
代码执行结果:
这么做的结果是,我们无法使用常规的方法处理它们,如果我们单个输出其中的每个字节,会发生什么呢?
co***le.log(''[0]);co***le.log(''[1]);
代码执行结果:
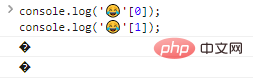
可以看到,单个输出字节是不能识别的。
好在St***g.fromCodePoint()和.codePointAt()两个方法是可以处理这种情况的,这是因为二者是最近才加入的。在旧版本的JavaScript中,只能使用St***g.fromCharCode()和.charCodeAt()两个方法转换编码和字符,但是他们不适用于特殊字符的情况。
我们可以通过判断一个字符的编码范围,判断它是否是一个特殊字符,从而处理特殊字符。如果一个字符的代码在0xd800~0xdbff之间,那么他是32位字符的第一部分,它的第二部分应该在0xdc00~0xdfff。
举个例子:
co***le.log(''.charCodeAt(0).toString(16));//d83 dco***le.log('?'.charCodeAt(1).toString(16));//de02
代码执行结果:

规范化
在英文中,存在很多基于字母的变体,例如:字母 a 可以是 àáâäãåā 的基本字符。这些变体符号并没有全部存储在UTF-16编码中,因为变化组合太多了。
为了支持所有的变体组合,同样使用多个Unicode字符表示单个变体字符,在编程过程中,我们可以使用基本字符加上“装饰符号”的方式表达特殊字符:
co***le.log('au0307');//ȧ co***le.log('au0308');//ȧ co***le.log('au0309');//ȧ co***le.log('Eu0307');//Ė co***le.log('Eu0308');//Ë co***le.log('Eu0309');//Ẻ
代码执行结果:
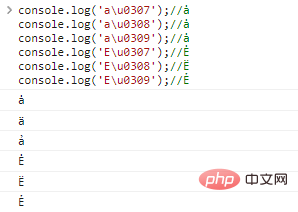
一个基础字母还可以有多个装饰,例如:
co***le.log('Eu0307u0323');//Ẹ̇ co***le.log('Eu0323u0307');//Ẹ̇
代码执行结果:
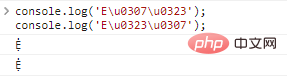
这里存在一个问题,在多个装饰的情况下,装饰的排序不同,实际上展示的字符是一样的。
如果我们直接比较这两种表示形式,却会得到错误的结果:
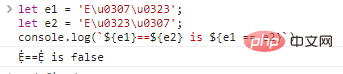
let e1 = 'Eu0307u0323';
let e2 = 'Eu0323u0307';
co***le.log(`${e1}==${e2} is ${e1 == e2}`)代码执行结果:
为了解决这种情况,有一个**Unicode规范化算法,可以将字符串转为通用**格式,由st***ormalize()实现:
let e1 = 'Eu0307u0323';
let e2 = 'Eu0323u0307';
co***le.log(`${e1}==${e2} is ${e1***rmalize() == e2***rmalize()}`)
代码执行结果:

【相关推荐:javascript视频教程、web前端】
以上就是JavaScript字符串常见基础方法精讲的详细内容,更多请关注php中文网其它相关文章!
